Apache Spark
24 Aug 2014Version checked 1.0.2
An open-source clustered data analytics framework
Highlights
Cluster computing Scala, Java & Python API Analytics Batch processing Stream processing (Real time)
Trade-off
Spark SQL MLib GraphX Spark Streaming Storage = Hadoop FS Shared variables ?
Overview
http://spark.apache.org/docs/latest/programming-guide.html
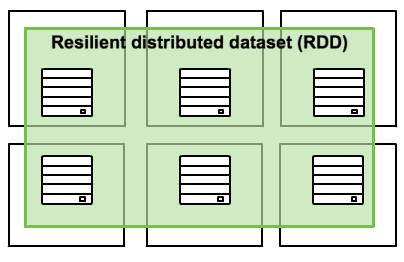
The main spark abstraction provides RDDs (Resilient distributed dataset) - A collection of elements partitioned across the nodes of a cluster, which can be operated in parallel.
RDDs are created by starting with a file in Hadoop filesystem (or any other Hadoop supported filesystem), it is possible to persist RDD in memory, allowing it to be reused efficiently across parallel operations. RDDs also recover node failures.
There is also the notion of shared variables. which can be used in parallel operations. Two possible types:
- Broadcast variables - Cache a value in memory (all nodes)
- Accumulators - Counters, Sums, etc
Shell
http://spark.apache.org/docs/latest/sql-programming-guide.html
Spark SQL
http://spark.apache.org/docs/latest/sql-programming-guide.html
MLib
http://spark.apache.org/docs/latest/mllib-guide.html
GraphX
http://spark.apache.org/docs/latest/graphx-programming-guide.html
Cluster mode
http://spark.apache.org/docs/latest/cluster-overview.html
Spark Streaming
http://spark.apache.org/docs/latest/streaming-programming-guide.html